ConfigMaps in Kubernetes erlauben es Umgebungsvariablen in den Cluster zu mappen. Dieses kann auch genutzt werden, um Konfigurationsdateien in den Cluster zu bringen. Dazu kann man mit kubectl create configmap eine Datei angeben, die dann in der ConfigMap bereitgestellt wird.
Ich möchte hier einen weiteren Weg zeigen, wie man Dateien in den Cluster bekommt. Dazu nutzen wir das Feature Multi Line Collections von YAML, welches erlaubt mehrere Zeilen zuzuweisen. Hier also die Konfigurationsdatei.
YAML Multi Line Collections
Multi Line Collection werden mit einen Senkrechtstrich | eingeleitet. Es muss wie bei YAML üblich die Einrückung berücksichtigt werden.
Beispiel
Hier ein einfaches Beispiel aus dem Liferay Deployment. Es wird die Elasticsearch Konfiguration von Liferay in den Kubernetes Cluster gemappt.
Mit K3D kann man lokal ein Kubernetes Cluster aus mehreren Nodes innerhalb von Sekunden erzeugen. Intern werden Docker Container mit K3S, um die Nodes zu erzeugen. Es ist zu empfehlen hier auf das Beta der Version 3 zu wechseln.
K3sup ist ein Tool um K3S lokal oder per SSH auf einem entfernten Rechner zu installieren. Da k3sup in GO geschrieben ist, besteht es auch nur aus einem Binary und besitzt keien weiteren Abhängigkeiten
yay --noconfirm -S minikube k3s-bin rancher-k3d-beta-bin
Kubernetes Tools
Introspektion
Name
Beschreibung
Homepage
k9s
Kommandoszeilentool mit dem man sehr einfach und schnell einen bestehenden Cluster untersuchen kann. Universelles Tool das man mit dem Kubernetes Dashboard für die Konsole vergleichen kann.
Findet alle Services in einem Namespace und erstellt ein Portforwarding für den Dienst ein und erstellt einen Eintrag in der /etc/hosts Datei, sodass sehr einfach auf die laufenden Dienste zugegriffen werden kann
Mit Stern kann man die Logausgaben meherer Container in mehreren Pods ausgeben lassen. Für eine gute Unterscheidbarkeit werden die Ausgaben der verschiedenen Container in unterschiedlichen Farben eingefärbt. Dieses erlaubt ein schnelleres Debugging in komplexen Setups
Mit Hilfe von einem Autodeployment in ein Kubernetes Cluster, werden Codeänderungen sofort wirksam und es werden Fehler überrsichtlich in einer Web UI dargestellt.
In diesem Artikel zeige ich wie man mit GitOps (FluxCD) einen Liferay Cluster in Betrieb nehmen kann. Voraussetzung ist das ein Kubernetes Cluster (z.B. mit K3D) mit FluxCD bereits läuft und ein passendes Git Repository mit den Deploy Keys zur Verfügung steht.
Es wird davon ausgegangen das die Verzeichnisse workloads und namespaces von FluxCD überwacht werden und FluxCD entsprechend konfiguriert ist.
Ferner muss die allgemeine Arbeitsweise von GitOps bekannt sein, d.h. es wird davon ausgegangen das sie wissen wie man zum Beispiel die Synchronisation manuell mit fluxctl auslösen kann, um die Arbeitsgeschwindigkeit zu erhöhen.
Ziel ist es einen kleinen Cluster mit 2 bis maximal 4 Instanzen von Liferay CE zu erzeugen.
Liferay Komponenten
Um Liferay CE bereitzustellen, benötigen wir einige Komponenten die wir nun der Reihe nach deployen werden. Wir werden zunächst einen Namespace erstellen und dann die Environment für Liferay erzeugen. Diese besteht aus Elasticsearch und der freien Datenbank MySql in der Version 8.0. Zusätzlich müssen wir für die Konfiguration von Elasticsearch und Liferay ConfigMaps erzeugen, damit alles zusammen funktioniert.
Namespace
Wir wollen simulieren, dass das Liferay in einer Prod Umgebung laufen soll und daher erstellen wir zunächst einen passenden Namespace liferay-prod.
Erstellen sie in dem Git Repository in dem Verzeichnis namespaces folgendes liferay-prod.yaml
Erstellen sie das Kubernetes Manifest com.liferay.portal.search.elasticsearch6.configuration.ElasticsearchConfiguration.cfg in dem workloads Ordner mit folgenden Inhalt:
Wie das Inlining von Dateien in YAML funktioniert, dazu mehr in einem weiteren Artikel YAML Multiline Collections.
Die Datei wird später in dem Liferay Deployment in den Pfad /mnt/liferay/files/com.liferay.portal.search.elasticsearch6.configuration.ElasticsearchConfiguration.cfg gemounted. Von hier kopiert sich der Liferay Container die Konfiguration von Elasticsearch und wendet sie beim Starten des Containers an. So ist eine Konfiguration von außen möglich.
Liferay
Die liveness und readyness Proben sind hier mit Absicht etwas höher angesetzt, da ich davon ausgehe dass es zum Testen in einer VM gestartet wird. Das heißt aber auch das eine weitere Instanz erst nach 2 Minuten frühestens bereit steht.
Es werden sofort 2 Instanzen gestartet und maximal auf 4 in HPA (Kubernetes Horizontal Pod Autoscaler) erhöht. Das heißt man sollte hier für dieses Beispiel genügend Arbeitspeicher frei haben.
Die Konfigurationsdatei portal-ext.properties muss nach /mnt/liferay/files/portal-ext.properties gemappt werden, damit der Liferay Container sie beim Start kopieren und letztlich einbinden kann.
apiVersion: v1
kind: ConfigMap
metadata:
name: portal-ext.properties
namespace: liferay-prod
data:
portal-ext.properties: |
# This is main Liferay configuration file, common (shared) for all Liferay environments.
#
# Liferay Workspace will copy this file into Liferay bundle's root directory (= ${liferay.home})
# when Liferay bundle is being built.
##
## JDBC
##
jdbc.default.driverClassName=com.mysql.cj.jdbc.Driver
jdbc.default.url=jdbc:mysql://database:3306/lportal?dontTrackOpenResources=true&holdResultsOpenOverStatementClose=true&useFastDateParsing=false
jdbc.default.username=roto2
jdbc.default.password=roto2
##
## Retry JDBC connection on portal startup.
##
#
# Set the number of seconds to retry getting a JDBC connection on portal
# startup.
#
retry.jdbc.on.startup.delay=5
#
# Set the max number of times to retry getting a JDBC connection on portal
# startup.
#
retry.jdbc.on.startup.max.retries=5
##
## Company
##
company.default.name=Liferay Kubernetes
#
# This sets the default web ID. Omniadmin users must belong to the company
# with this web ID.
#
company.default.web.id=liferay.com
##
## Servlet Filters
##
#
# If the user can unzip compressed HTTP content, the GZip filter will
# zip up the HTTP content before sending it to the user. This will speed up
# page rendering for users that are on dial up.
#
com.liferay.portal.servlet.filters.gzip.GZipFilter=false
#
# The NTLM filter is used to provide NTLM based single sign on.
#
com.liferay.portal.servlet.filters.sso.ntlm.NtlmFilter=false
#
# The NTLM post filter is used to fix known issues with NTLM and ajax
# requests. See LPS-3795.
#
com.liferay.portal.servlet.filters.sso.ntlm.NtlmPostFilter=false
##
# # Cluster Link
# #
#
# Set this to true to enable the cluster link. This is required if you want
# to cluster indexing and other features that depend on the cluster link.
#
cluster.link.enabled=true
ehcache.cluster.link.replication.enabled=true
#
# Set this property to autodetect the default outgoing IP address so that
# JGroups can bind to it. The property must point to an address that is
# accessible to the portal server, www.google.com, or your local gateway.
#
cluster.link.autodetect.address=database:3306
Ingress
Kubernetes nutzt für das Routing in dem Cluster einen sogenannten Ingress Controller, dieser muss wissen wenn eine HTTP Anfrage kommt an wen er diese weiterreichen muss.
Damit Liferay in mehren Instanzen in dem Cluster laufen kann, muss sichergestellt sein, dass die Anfragen auf dem Server wieder landen, wo der Benutzer angemeldet ist.
K3S verwendet nicht den Standard Ingress Controller, sondern Treafik als Ingress Controller. Daher weicht hier die Konfiguration für das Sticky Session Cookie etwas ab.
Affinity auf true setzen
In dem Ingress Manifest muss affinity auf true gesetzt werden (s.o.). Mit kubectl describe kann das getestet werden.
GitOps setzt sich aus Git und Operations zusammen und beschreibt dass die Infrastruktur (infrastructure as code) selbst auch in einem Git Repository gehostet wird.
Es gibt also bei dem GitOps Verfahren zwei unterschiedliche Repositorys. Ein Repository für den Application Code und ein Repository für die Verwaltung der Infrastruktur in dem die Anwendung laufen soll. Da die Infrastruktur nun auch in einem Git Repository verwaltet wird, lässt sich zu jedem Zeitpunkt und/oder an anderen Orten eine identische Kopie der Anwendung schnell aufbauen. Auch die Nachverfolgbarkeit ist somit gegeben. Bei guter Dokumentation in den Commit Messages, kann jede Änderung auch gut nachvollzogen werden.
Push und Pull
Es gibt für GitOps zwei Varianten wie das realisiert werden kann. Es gibt Push und Pull-basierende Verfahren. Push-basierend bedeutet, dass von außen eine Anwendung die getätigten Änderungen in dem Git Repository im Kubernetes Cluster durchführt. Das klingt erst einmal gut, wenn man aus einer CI/CD Pipeline heraus die Änderungen durchführen kann. Das hat aber einen entscheidenden Nachteil, eine Anwendung von außen hat vollen Zugriff auf den Cluster. Bei dem Pull-basierenden Verfahren geschiet dieses aus dem Cluster heraus und ist daher für den Betrieb also sicherer. Ein Vertreter der Pull-basierenden ist Fluxcd und dieses werden ich hier in diesem Artikel mit einem lokalen Git Repository, welches mit Gitea gehostet wird verwenden, um die Infrastruktur der Anwendung zu beschreiben.
Fluxcd mit lokalen Gitea Host
Nun beschreibe ich wie man GitOps mit Fluxcd umsetzt. Als Werkzeuge hierfür verwende ich K3D, K3S und K9S.
erstellt. Damit kubectl und K9S auf den Cluster zugreifen können, müssen wir die Kubeconfig mit K3D mergen mit
k3d get kubeconfig -a
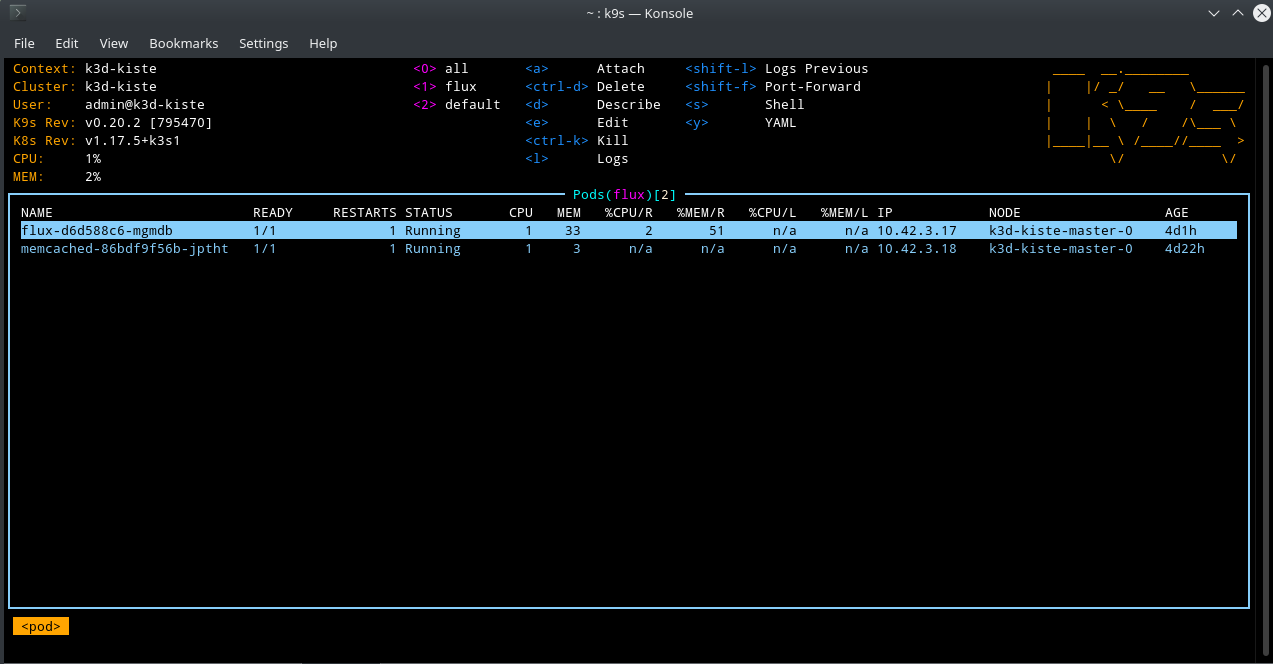
nun greifen die Tools auf den neu erstellten Cluster zu. Hier ein Screenshot von K9S mit dem man einen Kubernetes Cluster schön einfach über die Konsole inspizieren kann.
Alias für Kubectl
Wer es noch nicht eingerichtet hat, der sollte um die Schreibarbeit zu minimieren, ein alias k für kubectl mit
alias k=kubectl
einrichten.
Sollte kubectl noch nicht auf dem System installiert sein, dann kann es einfach mit:
yay -S kubectl
installiert werden.
Kubernetes Namespace
Es ist zu empfehlen, dass fluxcd in einem eigenen Kubernetes Namespace läuft. Ich wähle hierfür flux aus.
k create ns flux
Alternativ kann man den Namespace über ein Kubernetes Manifest flux.namespace.yaml anlegen lassen:
Es gibt 2 Varianten wie auf das Gitea Repository zugegriffen werden kann. Per HTTPS und SSH. Ich habe mich für die SSH Variante entschieden, weil so keine Credentials im Connection String angegeben werden muss und somit auch kein User vorhanden sein muss. Ich verwende SSH, weil so die Deployment Keys verwendet werden und ich der Anwendung fluxcd auf genau ein Repository Zugriff gewähren kann.
Damit per SSH auf das Gitea Repository zugegriffen werden kann, muss in dem fluxcd Kubernetes Deployment eine known_hosts Datei vorhanden sein, da sonst ein Zugriff auf das Gitea Repository nicht möglich ist und somit fluxcd das Repository nicht überwachen kann. Also muss man mit diese mit ssh-keyscan vorab erstellen.
ssh-keyscan gitea.xxx.org > known_hosts
Achtung: Falls der Git Server auf einem anderen Port lauscht, dann muss dieser mit -p spezifiziert werden. Nur so erhält man die richtigen Host Keys und eine korrekte known_hosts Datei.
Damit später aus dem Deployment von Fluxcd (siehe unten) darauf zugegriffen werden kann, muss die Datei als ConfigMap eingebunden werden.
k create configmap flux-ssh-config --from-file=known_hosts -n flux
Nun ist die ConfigMap in dem Namespace flux als flux-ssh-config bekannt. Darauf werden wir unten zugreifen.
YAML erstellen
Mit fluxctl install wird eine eine Multidatei YAML erzeugt. Diese wird über die Pipe per kubectl apply normalerweise direkt angewendet. Da wir aber für den Betrieb noch ein paar Anpassungen vornehmen müssen, leiten wir die Ausgabe in die Datei fluxcd.yaml um.
Zunächst muss fluxctl auf dem System installiert werden:
yay -S fluxctl
Danach erzeugen wir uns eine initiale YAML, die wir im Anschluss noch modifizieren werden.
# The following volume is for using a customised known_hosts
# file, which you will need to do if you host your own git
# repo rather than using github or the like. You'll also need to
# mount it into the container, below. See
# https://docs.fluxcd.io/en/latest/guides/use-private-git-host.html
- name: ssh-config
configMap:
name: flux-ssh-config
Die ConfigMap muss dem Cluster in dem vorher definierten Namespace flux bereitgestellt werden.
k create configmap flux-ssh-config --from-file=known_hosts -n flux
Jetzt muss die ConfigMap nur noch in den Container unter den Pfad /root/.ssh gemounted werden.
# Include this if you need to mount a customised known_hosts
# file; you'll also need the volume declared above.
- name: ssh-config
mountPath: /root/.ssh
Nur lese Modus
FluxCD bietet einen nur lese Modus an. Dieses ist praktisch, wenn man die volle Kontrolle über den Cluster behalten möchte. Anderenfalls scannt FluxCD die Imagerepository und aktualisiert per Commit neuere Versionen in den Kubernetes Manifesten.
# Tell flux it has readonly access to the repo (default `false`)
- --git-readonly
Einen Hostname einer festen IP Addresse zuordnen
Falls ein Dienst nicht per Namensauflösung im Container aufgerufen werden kann, dann kann man Hostnames definieren.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: flux
namespace: flux
spec:
replicas: 1
selector:
matchLabels:
name: flux
strategy:
type: Recreate
template:
metadata:
annotations:
prometheus.io/port: "3031" # tell prometheus to scrape /metrics endpoint's port.
labels:
name: flux
spec:
nodeSelector:
beta.kubernetes.io/os: linux
serviceAccountName: flux
volumes:
- name: git-key
secret:
secretName: flux-git-deploy
defaultMode: 0400 # when mounted read-only, we won't be able to chmod
# This is a tmpfs used for generating SSH keys. In K8s >= 1.10,
# mounted secrets are read-only, so we need a separate volume we
# can write to.
- name: git-keygen
emptyDir:
medium: Memory
# The following volume is for using a customised known_hosts
# file, which you will need to do if you host your own git
# repo rather than using github or the like. You'll also need to
# mount it into the container, below. See
# https://docs.fluxcd.io/en/latest/guides/use-private-git-host.html
- name: ssh-config
configMap:
name: flux-ssh-config
# The following volume is for using a customised .kube/config,
# which you will need to do if you wish to have a different
# default namespace. You will also need to provide the configmap
# with an entry for `config`, and uncomment the volumeMount and
# env entries below.
# - name: kubeconfig
# configMap:
# name: flux-kubeconfig
# The following volume is used to import GPG keys (for signing
# and verification purposes). You will also need to provide the
# secret with the keys, and uncomment the volumeMount and args
# below.
# - name: gpg-keys
# secret:
# secretName: flux-gpg-keys
# defaultMode: 0400
#
# map git.xxx.org to 192.168.2.1
#
hostAliases:
- ip: "192.168.2.1"
hostnames:
- "git.xxx.org"
containers:
- name: flux
# There are no ":latest" images for flux. Find the most recent
# release or image version at https://hub.docker.com/r/fluxcd/flux/tags
# and replace the tag here.
image: docker.io/fluxcd/flux:1.18.0
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 50m
memory: 64Mi
ports:
- containerPort: 3030 # informational
livenessProbe:
httpGet:
port: 3030
path: /api/flux/v6/identity.pub
initialDelaySeconds: 5
timeoutSeconds: 5
readinessProbe:
httpGet:
port: 3030
path: /api/flux/v6/identity.pub
initialDelaySeconds: 5
timeoutSeconds: 5
volumeMounts:
- name: git-key
mountPath: /etc/fluxd/ssh # to match location given in image's /etc/ssh/config
readOnly: true # this will be the case perforce in K8s >=1.10
- name: git-keygen
mountPath: /var/fluxd/keygen # to match location given in image's /etc/ssh/config
# Include this if you need to mount a customised known_hosts
# file; you'll also need the volume declared above.
- name: ssh-config
mountPath: /root/.ssh
# Include this and the volume "kubeconfig" above, and the
# environment entry "KUBECONFIG" below, to override the config
# used by kubectl.
# - name: kubeconfig
# mountPath: /etc/fluxd/kube
# Include this to point kubectl at a different config; you
# will need to do this if you have mounted an alternate config
# from a configmap, as in commented blocks above.
# env:
# - name: KUBECONFIG
# value: /etc/fluxd/kube/config
# Include this and the volume "gpg-keys" above, and the
# args below.
# - name: gpg-keys
# mountPath: /root/gpg-import
# readOnly: true
# Include this if you want to supply HTTP basic auth credentials for git
# via the `GIT_AUTHUSER` and `GIT_AUTHKEY` environment variables using a
# secret.
# envFrom:
# - secretRef:
# name: flux-git-auth
args:
# If you deployed memcached in a different namespace to flux,
# or with a different service name, you can supply these
# following two arguments to tell fluxd how to connect to it.
# - --memcached-hostname=memcached.default.svc.cluster.local
# Use the memcached ClusterIP service name by setting the
# memcached-service to string empty
- --memcached-service=
# This must be supplied, and be in the tmpfs (emptyDir)
# mounted above, for K8s >= 1.10
- --ssh-keygen-dir=/var/fluxd/keygen
# Replace the following URL to change the Git repository used by Flux.
# HTTP basic auth credentials can be supplied using environment variables:
# https://$(GIT_AUTHUSER):$(GIT_AUTHKEY)@github.com/user/repository.git
- --git-url=gitea@git.xxx.org:Kubernetes/fluxdemo.git
- --git-branch=master
- --git-path=namespaces,workloads
- --git-label=flux
- --git-user=sascha
- --git-email=sascha@edvpfau.de
# Include these two to enable git commit signing
# - --git-gpg-key-import=/root/gpg-import
# - --git-signing-key=<key id>
# Include this to enable git signature verification
# - --git-verify-signatures
# Tell flux it has readonly access to the repo (default `false`)
- --git-readonly
# Instruct flux where to put sync bookkeeping (default "git", meaning use a tag in the upstream git repo)
# - --sync-state=git
# Include these next two to connect to an "upstream" service
# (e.g., Weave Cloud). The token is particular to the service.
# - --connect=wss://cloud.weave.works/api/flux
# - --token=abc123abc123abc123abc123
# Enable manifest generation (default `false`)
# - --manifest-generation=false
# Serve /metrics endpoint at different port;
# make sure to set prometheus' annotation to scrape the port value.
- --listen-metrics=:3031
# Optional DNS settings, configuring the ndots option may resolve
# nslookup issues on some Kubernetes setups.
# dnsPolicy: "None"
# dnsConfig:
# options:
# - name: ndots
# value: "1"
---
apiVersion: v1
kind: Secret
metadata:
name: flux-git-deploy
namespace: flux
type: Opaque
---
# memcached deployment used by Flux to cache
# container image metadata.
apiVersion: apps/v1
kind: Deployment
metadata:
name: memcached
namespace: flux
spec:
replicas: 1
selector:
matchLabels:
name: memcached
template:
metadata:
labels:
name: memcached
spec:
nodeSelector:
beta.kubernetes.io/os: linux
containers:
- name: memcached
image: memcached:1.5.20
imagePullPolicy: IfNotPresent
args:
- -m 512 # Maximum memory to use, in megabytes
- -I 5m # Maximum size for one item
- -p 11211 # Default port
# - -vv # Uncomment to get logs of each request and response.
ports:
- name: clients
containerPort: 11211
securityContext:
runAsUser: 11211
runAsGroup: 11211
allowPrivilegeEscalation: false
---
apiVersion: v1
kind: Service
metadata:
name: memcached
namespace: flux
spec:
ports:
- name: memcached
port: 11211
selector:
name: memcached
---
# The service account, cluster roles, and cluster role binding are
# only needed for Kubernetes with role-based access control (RBAC).
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
name: flux
name: flux
namespace: flux
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
labels:
name: flux
name: flux
rules:
- apiGroups: ['*']
resources: ['*']
verbs: ['*']
- nonResourceURLs: ['*']
verbs: ['*']
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
labels:
name: flux
name: flux
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flux
subjects:
- kind: ServiceAccount
name: flux
namespace: flux
Starten
k apply -f ./fluxcd.yaml
Warten bis das Rollout durch ist
k -n flux rollout status deployment/flux
Die Deploy Keys auslesen
Beim Start erstellt fluxcd automatisch eine Identität, mit der dann auf das Git Repository zugegriffen werden kann. Dieses kann man mit in der Logs greppen…
k logs deployment/flux -n flux | grep pub
aber fluxcd kennt mit fluxctl identity eine eigene Anweisung, um die Keys zu extrahieren.
fluxctl identity --k8s-fwd-ns flux
Achtung: Die Deploy Keys werden nur erzeugt, wenn man das SSH Protokoll verwendet! FluxCD kann auch eine Verbindung zu dem Git Repository über eine HTTPS Verbindung aufbauen (siehe oben).
Sync manuell anstoßen
Normalerweise prüft fluxcd alle 5 Minuten das repository auf Änderungen. Gerade für den 1. Test ist das zu lange und daher stoßen wir mit fluxctl sync den Vorgang manuell an.
Das CLI Tool K9S ist ein sehr nützliches Werkzeug, wenn man in dem Cluster kein Kubernetes Dashboard laufen hat. Es bietet eine schnelle Navigation in dem Cluster und man kann sehr einfach Deployment anzeigen und verändern. Auch das Attachen oder ein Blick in die Logs ist mit dem Tool einfach mööglich. K9S wird aktiv weiterentwickelt und es erscheinen regelmäßig neue Versionen.
Installation von K9S
Wie immer verwende ich Manjaro für die Installation. Auf der Homepage von K9S sind aber alternative Installationsmöglichkeiten gezeigt, sodass jeder schnell das Tool zum Einsatz bringen kann.
yay -S k9s
Container
Ist man in einem container so stehen folgende Funktionen bereit:
Shortcut
Funktion
a
Attach
l
Logs (kann auch als Default mit RETURN aufgerufen werden)
Ist ein Hilfsmittel um einen K3S Cluster mit Docker innerhalb weniger Sekunden aufzusetzen. Hierbei wird eine Installation von K3S auf dem Host nicht benötigt, da K3S in Docker Containern gestartet wird. Wenn einmal die Docker Images geladen sind und lokal vorliegen, dann lässt sich sogar auf einem älteren Laptop ein Cluster mit mehreren Nodes innerhalb weniger Sekunden starten.
Installation
Die Installation erfolg über ein PKGBUILD, da
pkgname="rancher-k3d-bin"
pkgver=3.0.0b2
_pkgver=3.0.0-beta.2
pkgrel=1
pkgdesc='Little helper to run Rancher Labs k3s in Docker'
arch=('x86_64')
url='https://github.com/rancher/k3d'
license=('MIT')
provides=("k3d")
source=("${pkgname}-${_pkgver}::https://github.com/rancher/k3d/releases/download/v$_pkgver/k3d-linux-amd64")
md5sums=('563d008cf92dbe42afe280b0930a0d79')
package() {
install -Dm 0755 ${pkgname}-${_pkgver} "$pkgdir/usr/bin/k3d"
}
Die Version 3.0.0 befindet sich aktuell noch in der Entwicklung, aber da sie einige wichtige Änderungen beinhaltet, werde ich hier auf die Beta setzen. Diese scheint aber bereits ausgereift, so dass sie getestet werden kann. Bislang gab es keine Probleme.
Einen Cluster erstellen
Wie bereits beschrieben, lässt sich ein Cluster sehr einfach und schnell starten. K3D benötigt hierzu nur wenige Parameter. Der Cluster soll den Namen Demo erhalten und insgesamt 3 Worker (Nodes) bereitstellen. Zusätzlich wird ein Portmapping eingerichtet, sodass auf die Anwendung von außen zugegriffen werden kann.