Jeder kennt es, es ist ein neuer Cluster aufgesetzt und ggf. sind restriktive Firewall Regeln ein möglicher Grund für ein Delpoyment. Oder es wird anderweitig mal auf die Schnelle ein WebContent benötigt. Z.B. eine WebComponent die integriert werden soll.
Natürlich kann man schnell einen NginX spawnen, aber mir ist das zu schwergewichtig. Daher möchte ich euch eine leichtgewichtige Methode zeigen. In der man unter einer Minute Content aus dem aktuellen Verzeichnis ausliefern kann.
k8sdebug
Ich hatte ja bereit k8sdebug vorgestellt. Ein Helferlein, um schnell einen Container zu spawnen. Wir nutzen hier in dem Beitrag k8sdebug, um Alpine Linux Shell zu öffnen.
Python3 to the rescue
Ok, dann legen wir mal los. Zunächst erstellen wir einen Namespace, damit wir ggf. anderen Anwendungen nicht stören.
k create namespace www
Starten wir nun die Shell in Alpine:
k8sdebug alpine www
Jetzt brauchen wir Python3. Das ist schnell installiert.
Erstellen wir unsere Demo Content der ausgeliefert werden soll. Es ist kein echtes HTML, aber das spielt hier auch keine Rolle.
echo "Hello World!!!" > index.html
Jetzt haben wir auch schon alle Zutaten die wir benötigen. Starten wir nun den WebServer
python3 -m http.server
Das war es nun kann das Verzeichnis in bzw. die index.html auf dem Port 8000 des POD aufgerufen werden
Alternative kann auch mit Port-Forwarding der Inhalt von außen im Browser betrachtet werden.
k portforward -n www debug 8000
Im Browser wird nun der Inhalt des Demo Content angezeigt.
Hinweis: Da die Datei index.html heißt wird diese auch bei / ausgelifert. Möchte man im Dateisystem Browsen, dann muss man die Datei einfach umbennen, dann kann man im Browser das Verzeichnis durchsuchen und sich die Dateien anzeigen lassen.
Einzelne Dateien kann man bekannterweise mit kubectl cp in einen POD kopieren. Das wird umständlich, wenn man mehrere Dateien bzw. den Inhalt eines Verzeichnis kopieren möchte. Dieser Artikel soll eine Möglichkeit zeigen, die sehr schlank und ohne Abhängigkeiten auskommt. KSync verfolgt hier einen anderen Ansatz und verwendet unter der Haube Syncthing, um die Verzeichnisse bidirektional zu synchronisieren.
Beispiel Liferay
Die Portalsoftware Liferay basiert auf OSGi Technologie und bietet mit der Autodeployfunktion ein HotReload von Bundles an. Die Entwicklung der Bundles findet lokal statt und soll im Cluster getestet werden. In diesem Beispiel verwende ich einen lokalen K3D Cluster, um das Demo zu zeigen.
In dem Beispiel betreiben wir Liferay in einen Pod im Kubernetes Cluster und möchten mehrere Bundle Dateien aus einem Verzeichnis in den Containern in das Autodeploy Verzeichnis kopieren.
Dazu kann folgendes Skript als Grundlage dienen, um Dateien aus einem Verzeichnis zu kopieren.
#!/bin/bash
# Destination
NAMESPACE=liferay
LIFERAY_HOME=/opt/liferay
LIFERAY_DEPLOY=$LIFERAY_HOME/deploy
# Source
SRC=/dest
# get pod name
POD=`kubectl get pod -n $NAMESPACE -l app=liferay --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}'`
# copy files
tar -cvz -C $SRC . | kubectl exec -ti -n $NAMESPACE $POD -- sh -c "cd $LIFERAY_DEPLOY && tar -xzv"
Zunächst wird der POD Name ermittelt. Der Liferay POD ist mit app=liferay gelabelt, sodass der POD Name einfach über den Selektor zu ermitteln ist.
Dann wird das SRC mit allen Dateien als tar.gz gepackt und dann per sh Kommando wieder im Container entpackt.
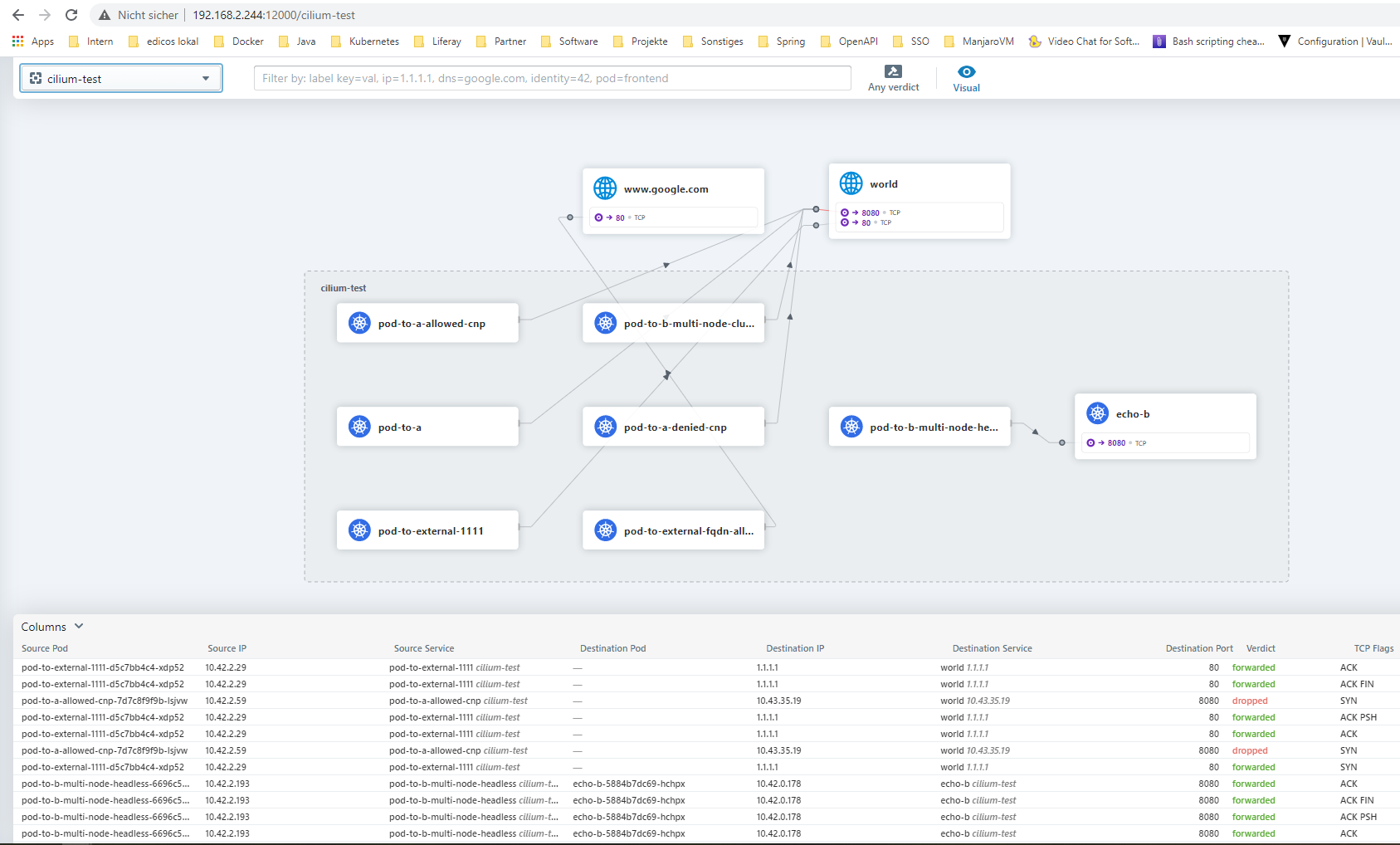
Mit Cilium steht Kubernetes ein mit von Google vorangetriebenes CNI zur Verfügung. Das Projekt Cilium nutzt eBPF Filter im Linux Kernel, um Kubernetes Network Policies effizient und performant umzusetzen. Durch die Verwendung von eBPF ergibt sich ein weiterer Vorteil. Es lassen sich alle Verbindungungen im Cluster tracken. Dieses kann mit Hubble UI im Browser visualisiert werden. Dadurch kann man schnell einen Überblick über die bestehenden Verbindungen erlangen und ggf. eingreifen, wenn unerwünschter Traffic erkannt wird.
Hubble
Für die Visualisierung der Verbidnungen im Browser kommt Hubble UI zu Einsatz. Zunächst muss man den gewünschten Namespace wählen und schon wird ein Graph gezeichnet, der die Verbindungen im Browser anzeigt. Es wird ein gerichteter Graph mit den Abhängigkeiten der Pods erzeugt und auch eine Tabellarische übersicht geboten. Mit klick auf einen Pod kann eine Filterung gesetzt werden. So lässt sich schnell der angezeigte Traffic filtern und analysieren.
Setup K3D Cluster
Für das Beispiel verwende ich K3D, um einen Demo Cluster zu erstellen. Dieses geht wie immer schnell von der Hand.
Konfiguration
Zunächst definieren wir den Clusternamen, die Anzahl der Worker und den API Port als Environment Variablen, um sie später zu nutzen:
Hinweis: Um Cilium zu nutzen müssen der LoadBalancer und Traefik nicht disabled werden. Die Komponenten habe ich nur aus Performancegründen ausgeschaltet, damit der Cluster schneller hochfährt. Sie sind für die Demo nicht relevant. Wichtig ist, dass mit –flannel-backend=none kein CNI Plugin automatisch installiert und das über –disable-network-policy der Defautl Network Policy Controller nicht geladen wird.
Korrektur der Initialisierung von Cilium
Da K3S keine Bash unter /bin/bash vorhält, funktioniert die Initialisierung von Cilium nicht korrekt. Daher muss hier manuell eingegriffen werden, um BPF Filter zu kompilieren.
for AGENT in $(seq 0 ${CLUSTERWORKER+1} 1)
do
docker exec -it k3d-$CLUSTERNAME-agent-$AGENT mount bpffs /sys/fs/bpf -t bpf
docker exec -it k3d-$CLUSTERNAME-agent-$AGENT mount --make-shared /sys/fs/bpf
done
docker exec -it k3d-$CLUSTERNAME-server-0 mount bpffs /sys/fs/bpf -t bpf
docker exec -it k3d-$CLUSTERNAME-server-0 mount --make-shared /sys/fs/bpf
Die shared mount müssen auf allen Nodes (agents) und Server ausgeführt werden. Dazu muss ggf. der Server Block angepasst werden. Je nach dem wieviele Agents und Server ihr beim Erstellen des Clusters angegeben habt.
Cilium und Hubble installieren
Die Installation von Cilium und Hubble ist eigentlich trivial.
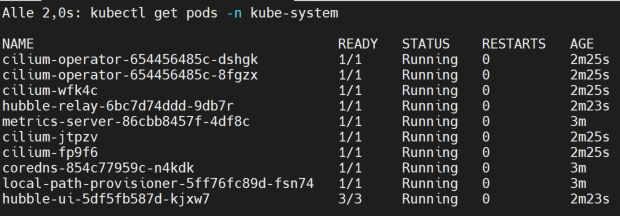
Nun watch warten bis alle Pods up and running sind
watch kubectl get pods -n kube-system
Hinweise zum Parameter KubeProxyReplacement
In den Blogeinträgen die man zum Thema Cilium und K3D im Internewt findet beschreiben immer das der Parameter kubeProxyReplacement auf partial stehen soll. Damit lies sich der Cluster aber nicht zum Laufen bewegen. Nicht einmal CoreDNS konnte mit der Einstellung deployt werden. Mit der Einstellung –set kubeProxyReplacement=disabled hingegen fährt der Cluster hoch und alles funtkioniert.
Port-Forwarding
Um Hubble im Browser zu öffnen muss noch ein Port-Forwarding eingerichtet werden. Dann kann unter http://localhost:12000/kube-system aufgerufen werden.
Jetzt kann man in der UI zuschauen, wie sich der Traffic ändert und die verschiedenen Verbindungen in der UI analysieren.
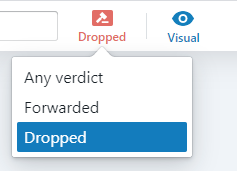
Network Policies überprüfen
Wenn man eine neue Regel für Kubernetes Network Policies erstellt hat, dann taucht bestimmt die Frage der Wirksamkeit auf. Auch dieses lässt sich schön über die Oberfläche der Hubble UI darstellen. Dazu muss man oben in der Toolbar
In diesem Artikel zeige ich wie man einfach einen Pull through Cache für K3D nutzt, um auch beim Löschen eines Clusters vom Caching von größen Images zu profitieren.
K3D
Ein Kubernetes Cluster der mit K3D/K3S aufgebaut ist, der hat ein integriertes Caching für Docker Images die aus einer Registry (docker.io oder quay.io) geladen werden. Solange also der Cluster steht und nicht mit delete gelöscht wird, hält K3D die Images innerhalb der Docker Container weiter vor. Dadurch wird der Netzwerkverkehr gesenkt und auch das erneute Deployen von Anwendungen erfolgt deutlich schneller.
K3D Registries
Seit kurzer Zeit besteht eine komfortable Möglichkeit eine Registry in K3D zu registrieren. Dazu muss man nur eine Registry Konfigurationsdatei angeben. In dieser werden die Parameter für die Konfiguration der Registry übergeben. Der Parameter –registry-config spezifiziert die Konfigurationsdatei.
Der Default registriert K3D den Hostname host.k3d.internal automatisch mit der IP des Hosts, sodass aus dem Cluster dieser hierüber angesprochen werden kann. In dem Beispiel möchte ich die docker.io und quay.io cachen. Trage wir dazu 2 Registries als Mirror in die Konfiguration ein:
Wir werden auf den lokalen Ports 5001 und 5002 des Hosts jeweils einen Pull through Cache installieren, sodass diese als Registries innerhalb des Clusters verwendet werden.
Docker Registry V2 und UI
Kommen wir nun zur Installation des Caches. Docker bietet mit dem Registry v2 Image selber eine Lösung hierfür an. Wichtig ist hierbei die Environment Variable REGISTRY_PROXY_REMOTEURL. Über diese kann eine Registry die angegeben werden, diese wird dann geproxied und das ist genau das wir für den Anwendungsfall benötigen.
Als UI kommt die https://github.com/Joxit/docker-registry-ui zum Einsatz. Diese bietet eine einfache UI, um den Inhalt der Registry anzuzeigen. Was in unserem Fall aber vollkommen ausreichend ist. Die UI wird über die Ports 6001 und 6002 analog zu den Registries bereitgestellt. Somit ergibt sich das folgende Dockerfile:
Git Repos lassen sich dennoch recht einfach als Volume in einen Container einbinden. Man muss dafür einen InitContainer verwenden, der das Repository auscheckt und in einem Verzeichnir bereitstellt. Diese mounted man per emptyDir{} in den Container. Nun stehen die zuvor ausgecheckten Dateien aus dem Repository im Container bereit.
Beispiel
# Beispiel wie man InitContainers für die Bereitstellung
# eines GIT Repository nutzt. Die GitRepo Volumes sind
# deprecated und sollten nicht mehr verwendet werden. Dieses
# Beispiel nutzt den Ansatz das Git klonen in einem
# InitContainer auszuführen.
apiVersion: v1
kind: Pod
metadata:
name: git-repository-demo
annotations:
seccomp.security.alpha.kubernetes.io/pod: 'docker/default'
spec:
initContainers:
# Dieser InitContainer klont das gewünschte Repository
# in das EmptyDir Volume Verzeichnis
- name: git-clone
image: alpine/git # Alpine Linux mit Git
args:
- clone
- --single-branch
- --
- https://github.com/test/testrepo # Das Repository
- /repo # Put it in the volume
securityContext:
runAsUser: 1 # Hier ggf. Anpassungen vornehmen
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
volumeMounts:
- name: git-repo
mountPath: /repo
containers:
# Hier muss das richtige Image angegeben werden
# das genutzt werden soll. Bsp. BusyBox
- name: busybox
image: busybox
args: ['tail','-f','/dev/null'] # Demo tue nichts
volumeMounts:
- name: git-repo
mountPath: /repo
volumes:
- name: git-repo
emptyDir: {}
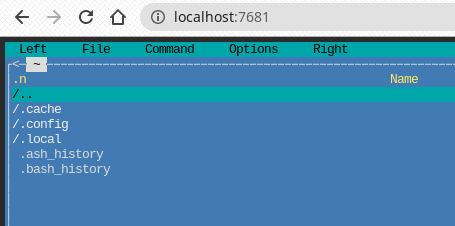
Das Projekt https://github.com/tsl0922/ttyd erlaubt den Zugriff auf ein Linux über einen Web Browser. In diesem Beispiel verwende ich die Alpine Version des Images von Docker Hub. Es ist mit rund 4MB sehr klein und ist daher sehr schnell erstellt.
Mit kubectl ist ttyd per run zu starten. Per default lauscht ttyd auf dem Port 7681. Das heißt damit man auf die WebShell zugreifen kann muss der Port Forward mit ausgeführt werden.
kubectl run --image=tsl0922/ttyd:alpine --port=7681 ttyd
kubectl port-forward ttyd 7681:7681 --address=0.0.0.0&
Midnight Commander
Als Beispiel für die volle funtkionstüchtigkeit habe ich per apk add mc den MC installiert.
Wenn man mit K3D einen neuen Cluster anlegt, dann wird Treafik V1 per Default über Helm anstatt Nginx ausgerollt. Das ist oft nicht von Relevanz, aber einige Anwendung setzen für den Betrieb den NginX als Ingress Controler voraus.
K3D ohne Traefik
Man kann K3S –k3s-server-arg ‘–no-deploy=traefik’ nun K3S veranlassen Traefik nicht auszurollen, um NginX als Ingress Controller zu installieren.
K3S schaut beim Start in dem Verzeichnis /var/lib/rancher/k3s/server/manifests/ nach Manifesten. Man kann also hier das CRD für NginX ablegen und das führt. Mehr dazu unter https://rancher.com/docs/k3s/latest/en/helm/.
Jetzt muss man beim Start von dem K3D Cluster den Parameter volume übergeben, sodass die Datei helm-ingress-nginx.yaml in den Container in den Pfad gemappt wird.
Die Fehlersuche in Kubernetes ist manchmal aufgrund der restriktiven Container Images nicht ganz trivial, da wichtige Tools für das Debugging fehlen.
Am einfachsten ist es einen weiteren POD zu Starten, um von dort die Fehlersuche durchzuführen.
Kubernetes “run” – to the Rescue!
Kubernetes besitzt mit run wie bei Docker auch einen Container zu starten. Dieses nutzen wir nun, um einen weiteren temporären Container zu starten. Sehr leichtgewichtige Images sind Busybox und Alpine, was ein schnelles hochfahren ermöglicht.
Bash Funktion
# open debug shell
k8sdebug() {
case "$#" in
"2")
kubectl run -i --tty --rm debug --image=$1 -n $2 --restart=Never -- sh
;;
"1")
kubectl run -i --tty --rm debug --image=busybox -n $1 --restart=Never -- sh
;;
"0")
echo "Synopsis: k8sdebug [imagename] namespace"
echo "if no image is specified busybox is used"
echo "e.g.: k8sdebug alpine liferay-dev to start an alpine linux in namespace liferay-dev"
esac
}
Beispiele
Hier noch ein paar Anregungen für den Einsatz der Debug-Shell.
Wget
Wer nur wget benötigt, der kann auf Busybox Image starten. Es muss nur der Namespace angegeben werden.
[sascha@vbox ~]$ k8sdebug liferay
If you don't see a command prompt, try pressing enter.
/ # wget
BusyBox v1.32.1 (2021-01-12 00:38:40 UTC) multi-call binary.
Usage: wget [-c|--continue] [--spider] [-q|--quiet] [-O|--output-document FILE]
[-o|--output-file FILE] [--header 'header: value'] [-Y|--proxy on/off]
[--no-check-certificate]
[-P DIR] [-S|--server-response] [-U|--user-agent AGENT] [-T SEC] URL...
Retrieve files via HTTP or FTP
--spider Only check URL existence: $? is 0 if exists
--no-check-certificate Don't validate the server's certificate
-c Continue retrieval of aborted transfer
-q Quiet
-P DIR Save to DIR (default .)
-S Show server response
-T SEC Network read timeout is SEC seconds
-O FILE Save to FILE ('-' for stdout)
-o FILE Log messages to FILE
-U STR Use STR for User-Agent header
-Y on/off Use proxy
/ #
Curl
Möchte man lieber ein echtes Curl verwenden, dann ist alpine linux die beste Wahl.
In der aktuellen Version von K3D wird in K3S CoreDNS für die Namesauflösung verwendet. Leider ist der Upstream Nameserver auf 8.8.8.8 voreingestellt, sodass es aus den Containern zu Problemen kommen kann, wenn man einen eigenen DNS hat und den für die Namensauflösung der Ingresses in dem Cluster sorgt.
So kann ein Ingress aus einem anderen POD heraus nicht über die Ingress URL aufgerufen werden.
Konfiguration des CoreDNS
Die Konfiguration erfogt über die Datei Corefile im Namespace kube-system.
Hier ist die Zeile mit forward . 192.168.2.1 Interessant. Diese bestimmt den Upstream DNS Server für CoreDNS. Hier muss also der lokale DNS eingetragen werden, dann kann man das Manifest anwenden und der DNS ist umkonfiguriert. Dann sollte die Namensauflösung in den Containern funktionieren.
Die Exportfunktion in dem KeyCloak, also über die Web UI, kann leider keinen Datenbank Dump durchführen. D.h. es werden keine Secrets exportiert, was einen vollständigen Import beim Starten eines Clusters nicht möglich macht.
Dennoch gibt es von der Konsole aus die Möglichkeit einen Export durchzuführen. Dazu muss man das Binary standalone.sh mit der Aktion keycloak.migration.action=export aufrufen. Dann lässt sich ein Dump durchführen. In diesem Artikel beschreibe ich folgende Situation. Es soll aus einem laufenden KeyCloak Container die vorgenommenen Einstellungen gesichert werden, sodass diese bei einem Neustart wiederhergestellt werden. Ich setze hier einen K3D Kubernetes Cluster mit KeyCloak ein.
Auf die Einstellungen des REALMs gehe ich hier jetzt nicht weiter ein und spielt auch keine Rolle welche REALMs vorhanden sind.
Das Vorgehen ist wie folgt: Es muss der Name des PODs ermittelt werden. In dem Beispiel gehe ich davon aus, dass der KeyCloak in einem eigenen Namespane keycloak läuft und das mit dem Label app=keycloak versehen ist. Haben wir die Namen des PODs ermittelt, dann können wir eine zweite Instanz in dem Container von außen starten und den Export anstoßen. Leider beendet der KeyCloak sich nicht nach dem Export, sodass wir eine CTRL+C Handler installieren müssen. Die vollständige Dokumentation für die KeyCloak Im-/Export-Funktion finden sie hier.
Wichtig ist für den Start der neuen Instanz, dass ein beliebiger freier Port gewählt wird, da sonst der KeyCloak nicht starten würde. Dieses gilt für den HTTP und den Management Port.
Ist der KeyCloak hochgefahren, dann kann er mit STRG+C beendet werden und der Export wird aus dem Container in lokale Verzeichnis kopiert.
Das Skript
Zusammengefasst ergibt sich folgendes export.sh Skript:
#!/bin/bash
#
# to copy export file from container stop standalone.sh with CTRL+c
#
# retrieve POD name
POD_NAME=`kubectl get pod -n keycloak -lapp=keycloak --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}'`
# add CTRL-C Handler
trap trap_catch INT
function trap_catch() {
# copy exported config from container to local storage
kubectl cp keycloak/$POD_NAME:/tmp/keycloak-export.json test.json
}
# start new server
kubectl exec -n keycloak $POD_NAME bash -- /opt/jboss/keycloak/bin/standalone.sh -Dkeycloak.migration.action=export -Dkeycloak.migration.provider=singleFile -Dkeycloak.migration.file=/tmp/keycloak-export.json -Djboss.http.port=8888 -Djboss.https.port=9999 -Djboss.management.http.port=7777